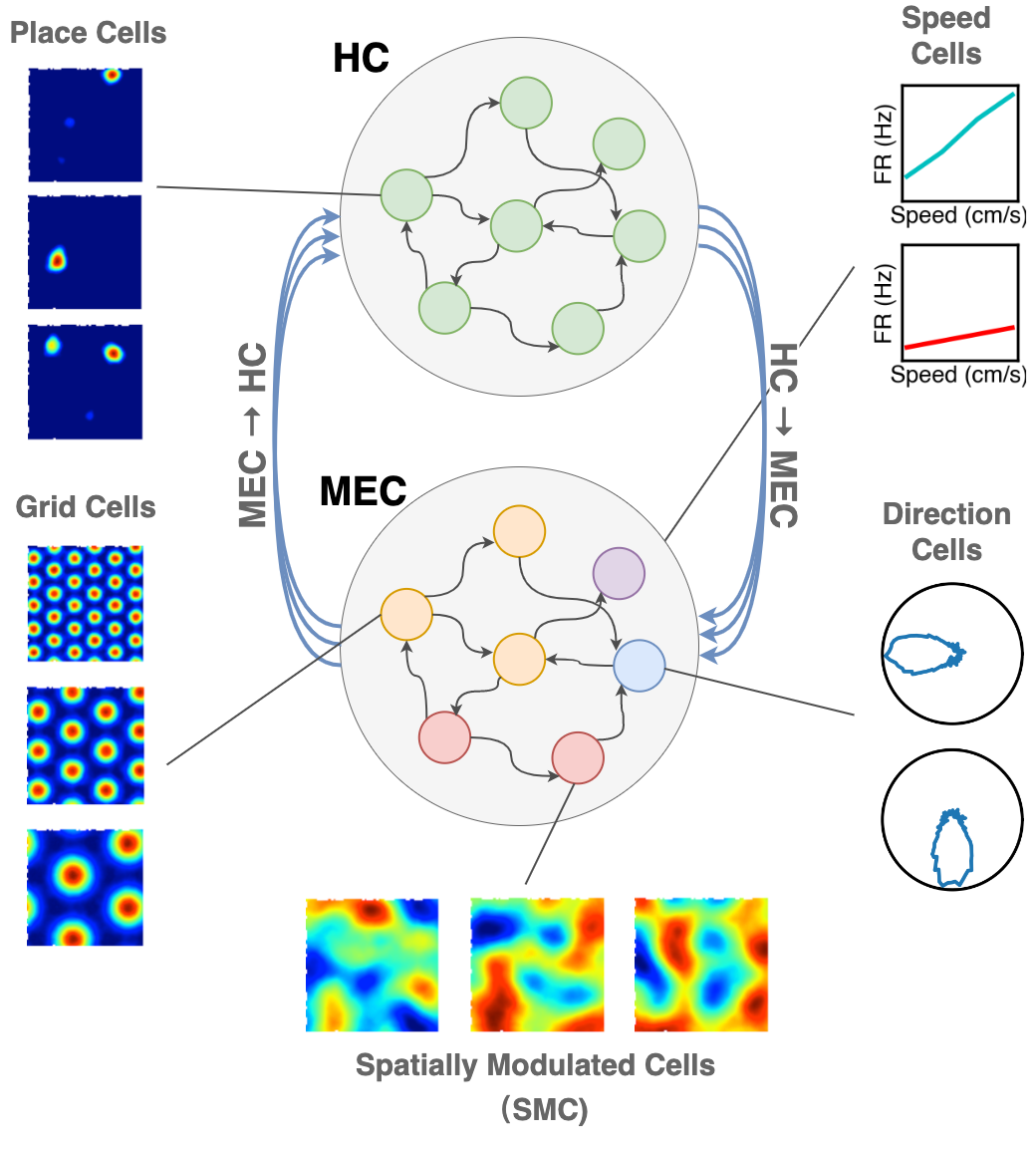
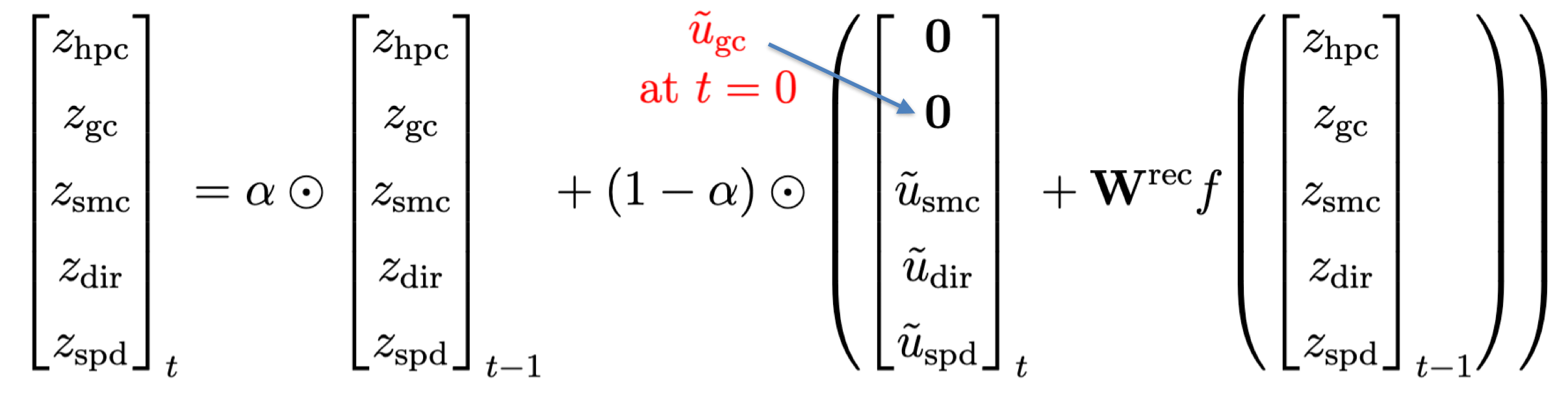
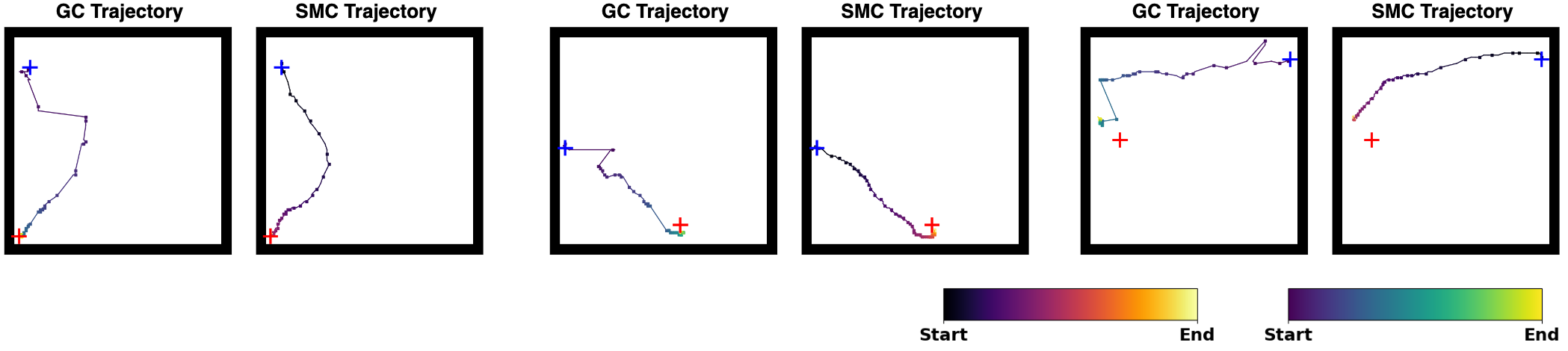
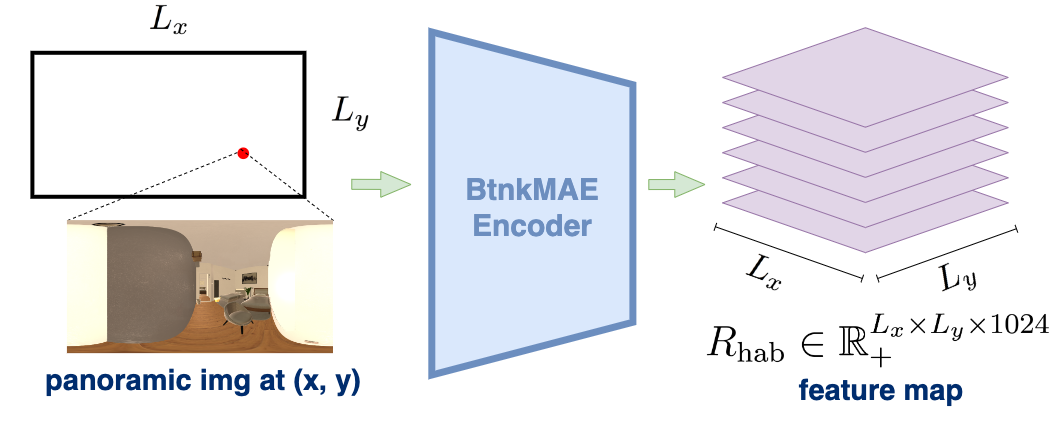
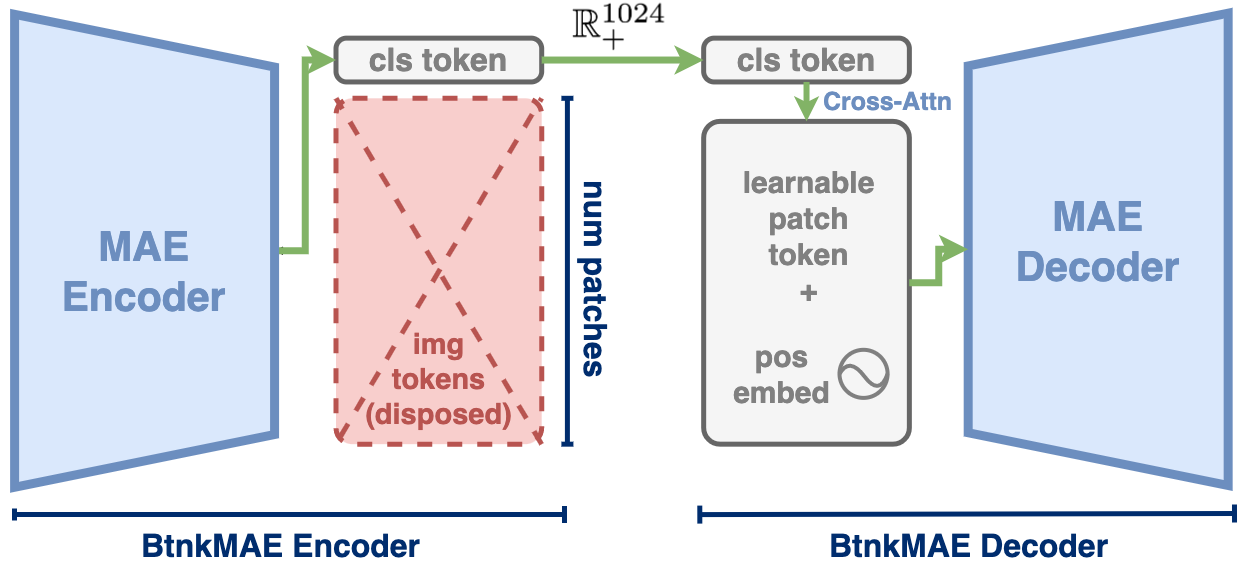
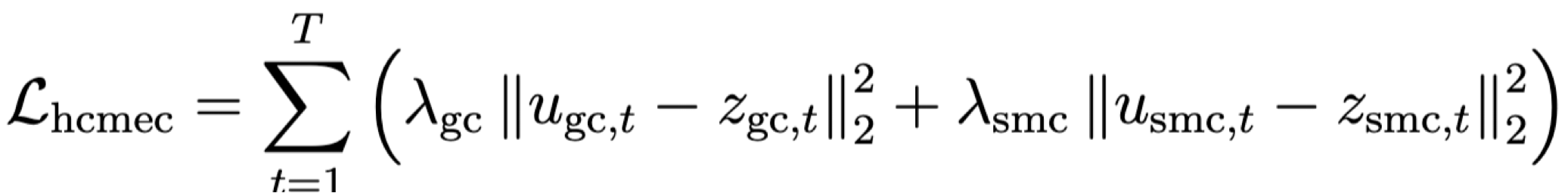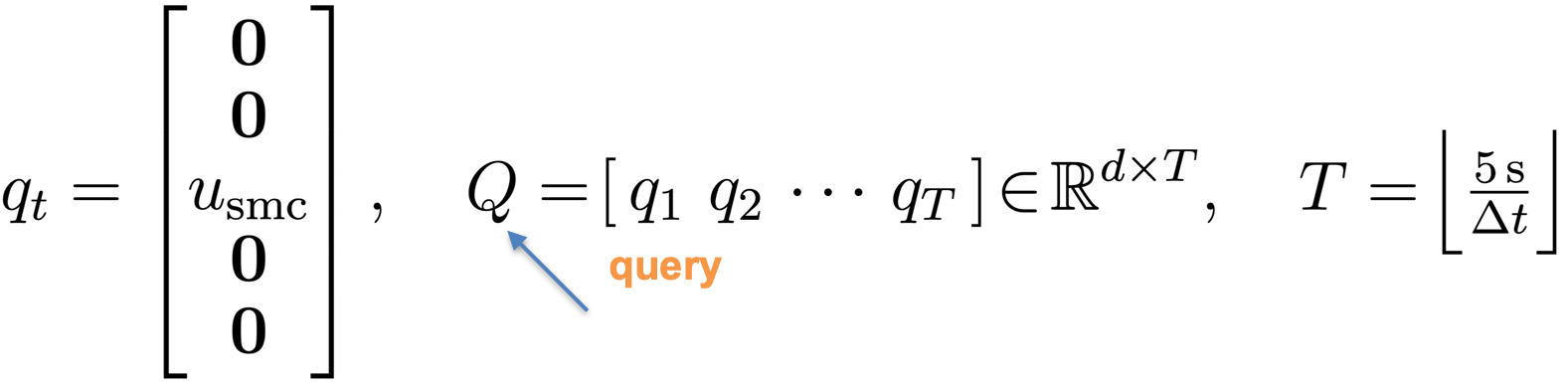Background
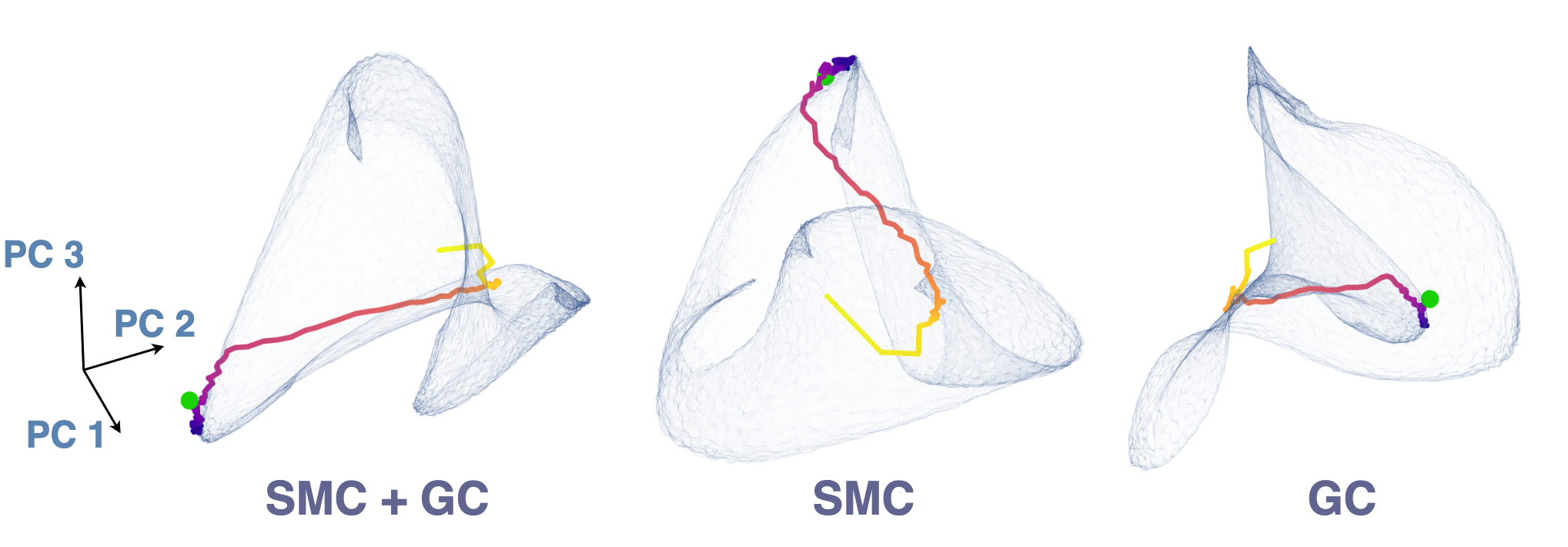
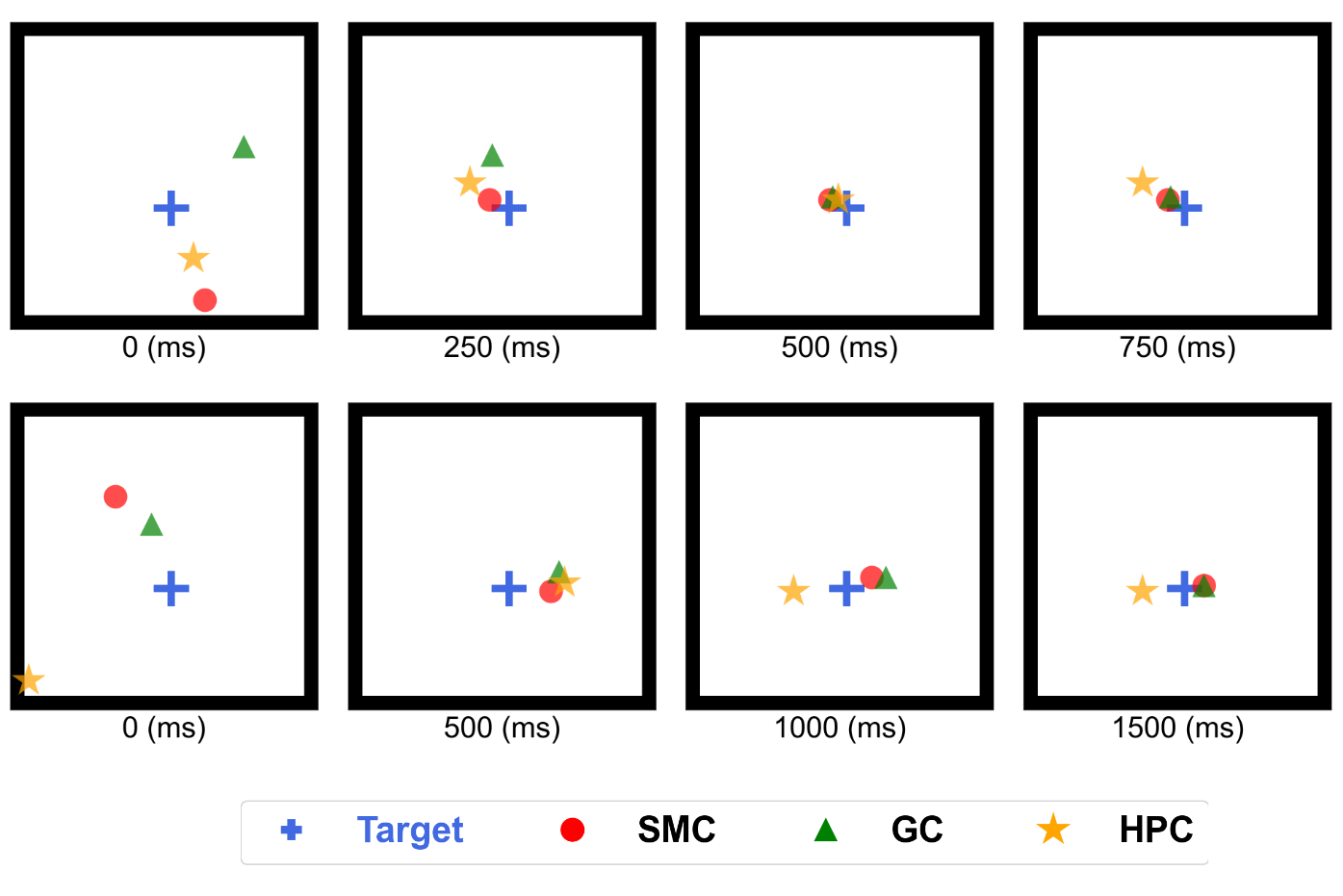
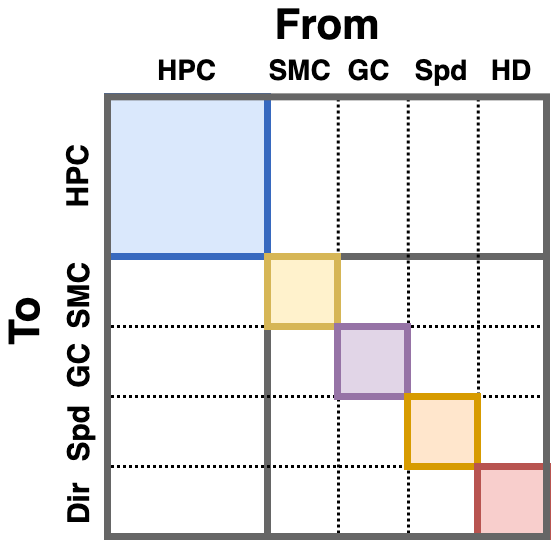
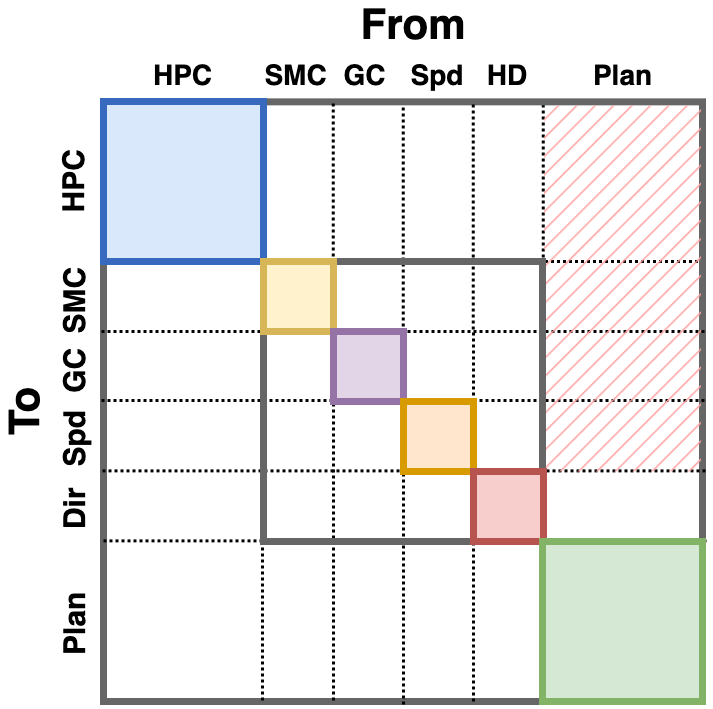
Decades of research have revealed multiple types of cells that support animals' navigation and localization.
For example, grid cells in the MEC fire in hexagonal patterns, while place cells in the hippocampus fire at specific locations.

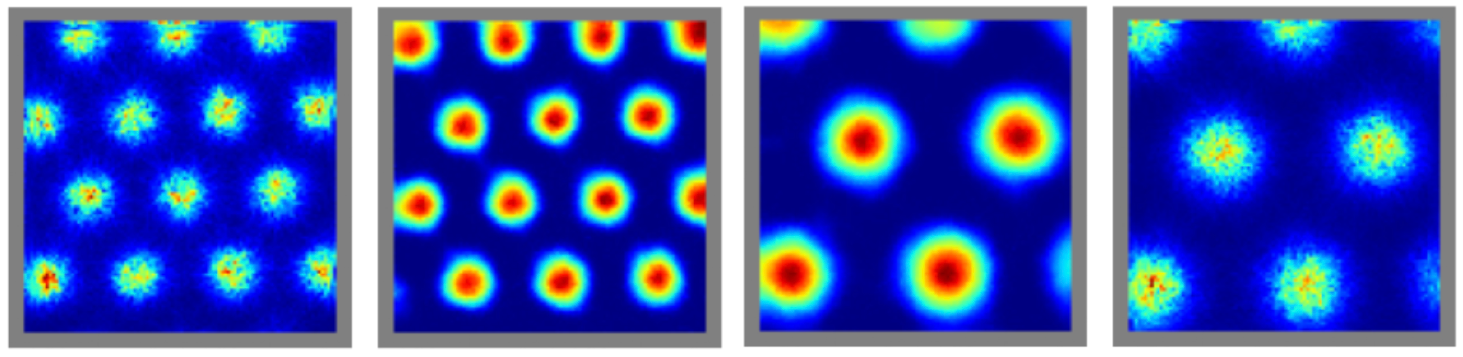
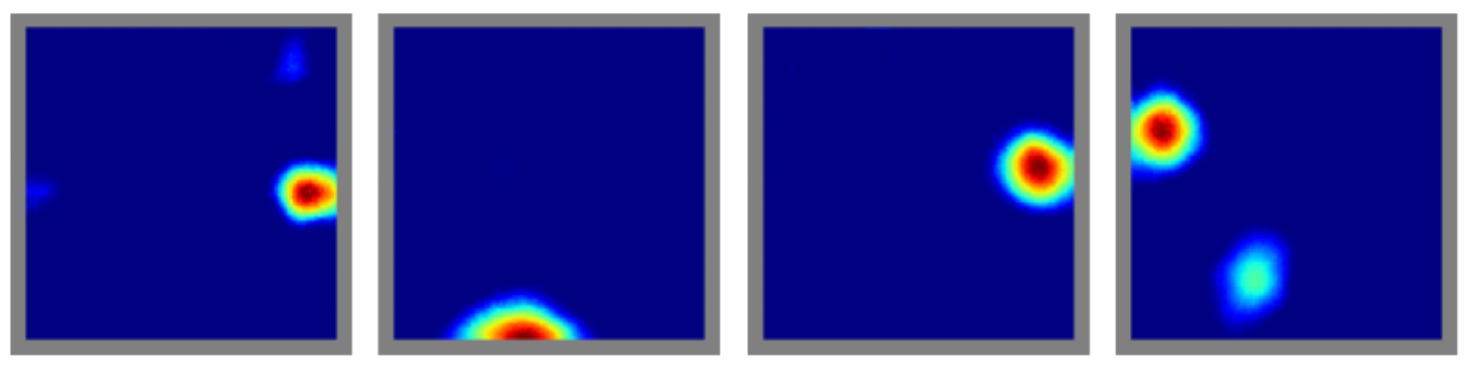
Example of grid cells
Example of place cells